
前言
阅读本文内容前,你可能需要了解的基础知识「端智能」基于自然语言处理 (NLP) 的光学字符识别 (OCR)
在最近的技术分享中,我们已经知道了实现「图像文字识别&提取」这个功能所需的基本技术方案和原理 ,这解决了我们实现这一功能当中 Why 和 What 的问题。但光知道 Why 和 What 还远远不够,我们还需要明确 How 的问题,也就是如何做。
注意:下文中所指的 NLP / NaturalLanguage、CoreML 和 Vision 均是代指,其中包含了大量需要手动编写代码实现的部分,这些框架只供给能力,并不能自动实现的,请不要混淆概念。
研发看这里
理清职责
首先,我们需要明确 NLP / NaturalLanguage、 CoreML 和 Vision 在这一过程中分别扮演了一个什么样的角色?
只有弄清楚这一点,才能有的放矢的设计我们的整套流程,以及规划我们的调研方向从何入手。但想要搞清楚这一点,我们就必须知道,在这一功能点上,他们分别能做什么和不能做什么。
Vision
我们需要知道一点,那就是 Vision 框架的文本识别是语言无关的,所以它会尝试识别图像中出现的所有文本,不论是中文、英文还是其他语言。如果希望对识别出的文本进行甄别,就需要我们另寻出路。所以,仅仅依靠 Vision 是不足以支撑图像识别和取词的。
CoreML
如果想要在识别结果中只获取英文并忽略其他语种或文字,那么我们就需要在识别过程完成后,对结果进行后处理。那谁又能做这件事呢?答案显而易见:CoreML。
现在我们再来看看 CoreML 擅长做什么事情,我们知道 CoreML 本身只是一个机器学习模型的使用和训练框架,在应用层面上,他对我们的意义就是如何使用某一个已经训练好的模型。识别并进行分类正好是模型擅长做的事情,所以我们需要做的事情就很明朗了,找到或自己训练出符合我们要求的模型。
模型表现是完全依赖训练效果的,而训练也是需要海量数据的成本,包括不同的字体、字号等等。开源免费的模型通常效果不佳,而精准模型又面临着使用成本和模型体积的问题。
NLP / NaturalLanguage
Vision 框架内置了一套 NLP 的神经网络,通过不同的识别请求配置,可以对语言进行基本的筛选区分以及矫正。但 Vision 存在一个显著的问题便是:其识别结果无法有效对文本进行分词等提炼,也无法精准识别每一个单词是属于什么语言。所以这时我们需要引入一个新的框架:NaturalLanguage。
NaturalLanguage 是比 Vision 更为底层的基础 NLP 神经网络框架,能够对识别文本做最细颗粒度的控制,包括但不限于与文本的切割处理方式、词性识别、语种、语法处理等等。我们需要的便是结合 Vision 和 NaturalLanguage,对识别结果做最精细的处理。
明确了职责,让我们看一下基本的流程如何。
核心流程
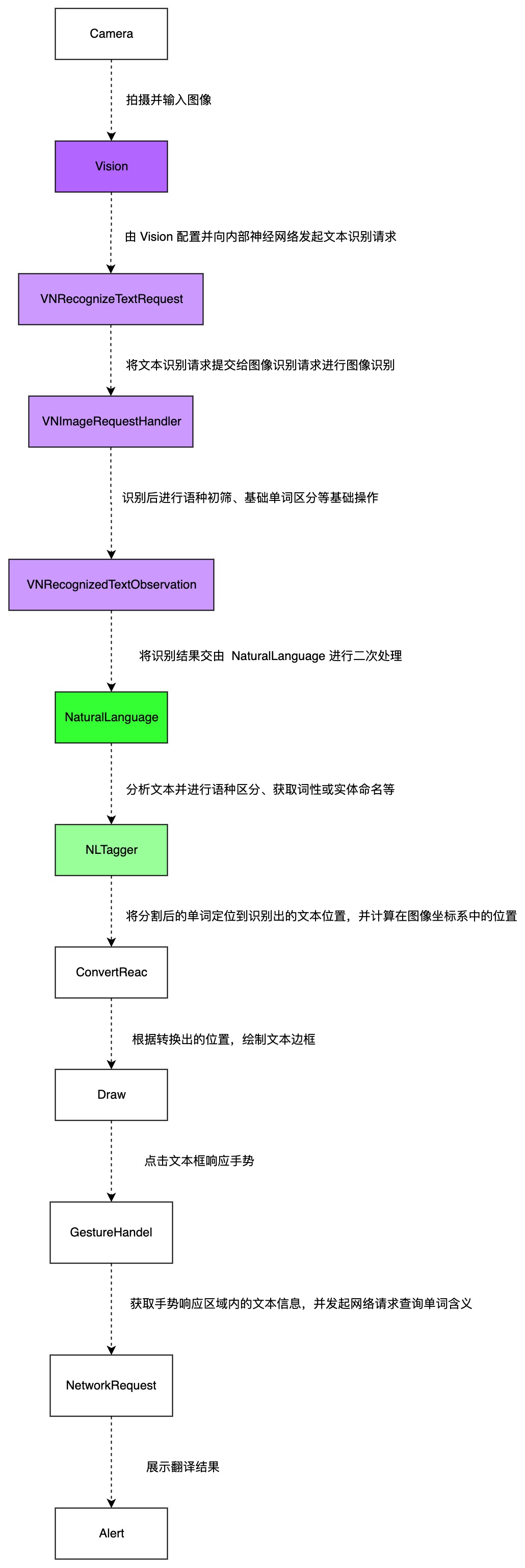
产品看这里
经过调研和产出,我们使用自研能力与另外两家目前主流的翻译词典 APP:网易有道词典、欧路词典挑选了同一网页进行对比,具体效果如下:
对比案例 A
多语种混合页面
网易有道词典
可以看到,在多语种混合页面当中,有道词典无法对不同语言、阿拉伯数字等干扰信息进行有效筛除和过滤,将图像中的所有文本全部识别进来,目前效果是几家里表现最糟糕的。显而易见,他们只拥有最初级的识别能力。
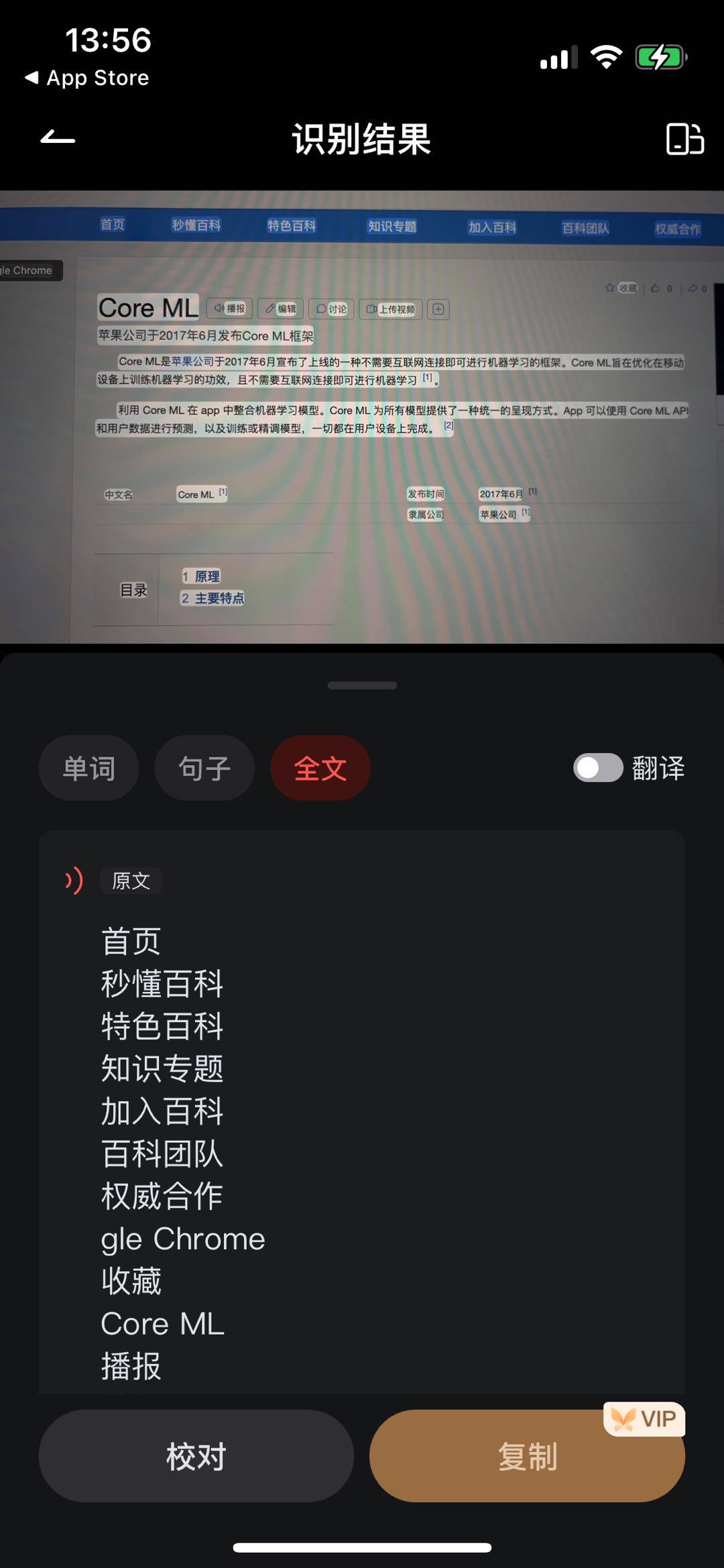
欧路词典
欧路词典的表现比有道词典略强,可以筛除一部分阿拉伯数字或中文等干扰信息,但表现也强差人意。欧陆在图像识别上花了一些功夫做了简单的语言甄别处理。
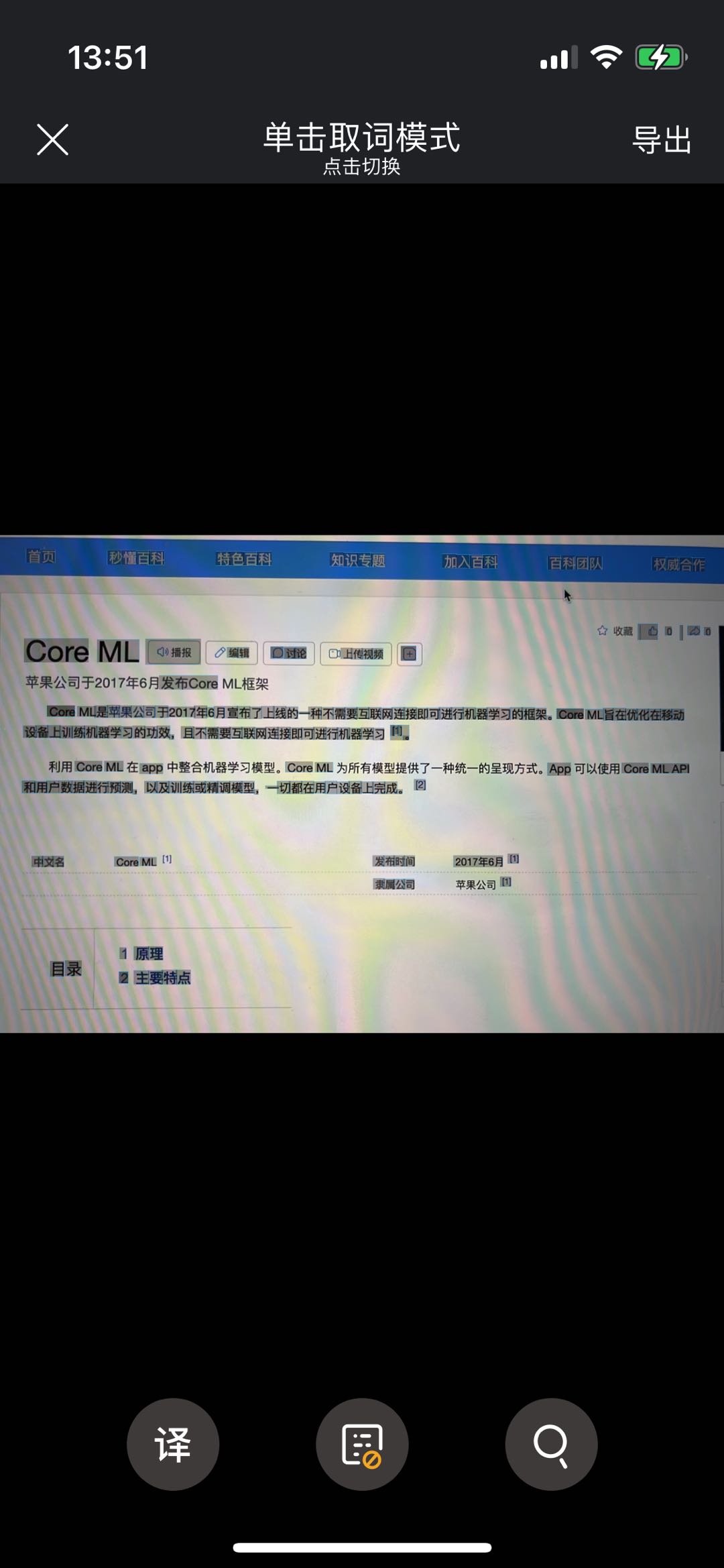
洋葱
我们的表现无疑是最好的,精细化的控制,精准的移除了非目标语言外一切干扰因素。
对比案例 B
英文主导页面,如英语试卷
网易有道词典
案例 A 别无二致,囊括所有图像中的文案
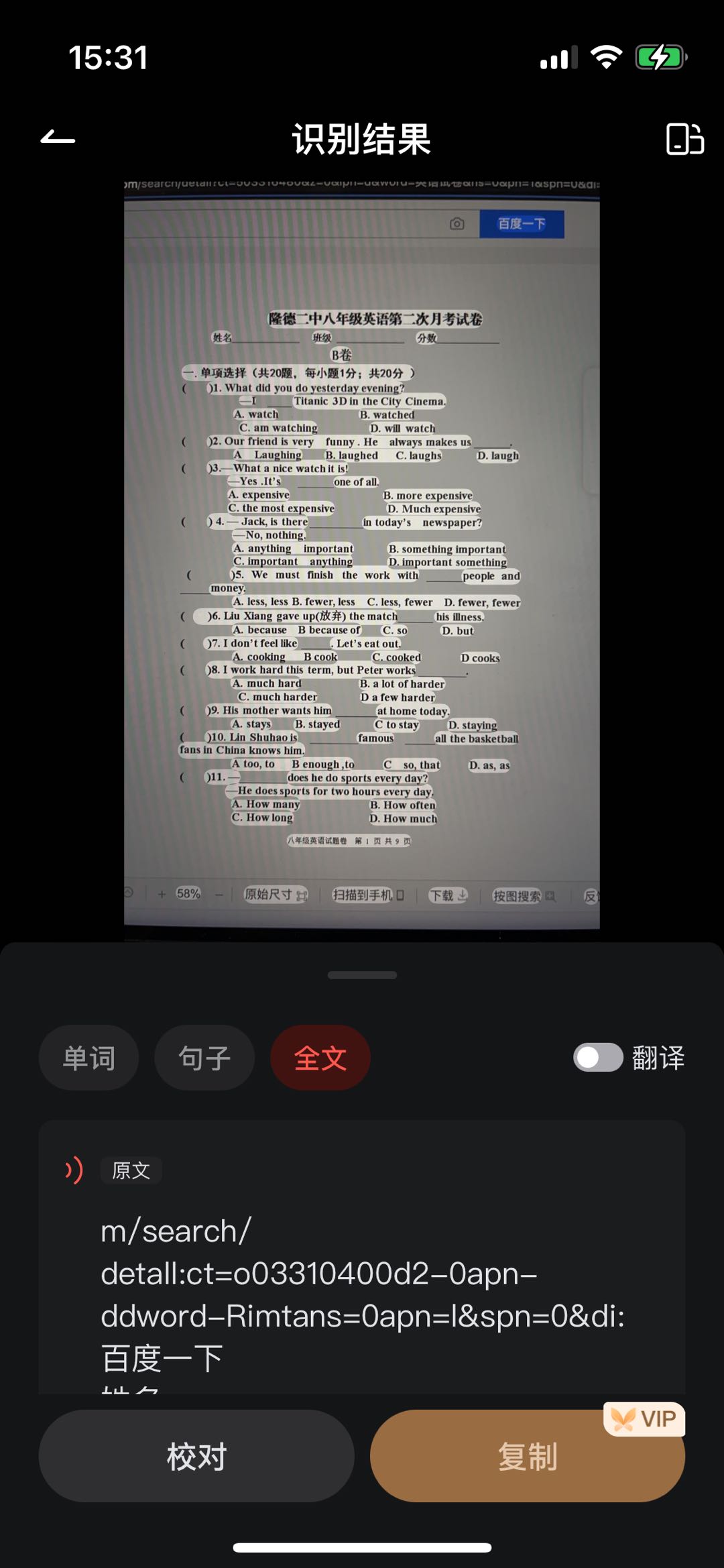
欧路词典
同样的,欧路依旧只能够做基础的甄别处理,过滤掉部分噪音。

洋葱
已无需多言。
具体识别精细度,受到印刷体清晰度和拍摄像素而定。
大家看过来
功能限制
目前有几点技术层面上的瓶颈,望周知:
- 目前神经网络的科学发展水平无法做到100%精准识别,受硬件、拍摄水平、印刷水平等等因素限制。
- iOS 的识别准确率随版本的提升而提升,受制于硬件驱动及训练模型,目前最准确的版本需要至少保持 iOS 16 及以上系统才可生效,以下版本的准确率会略低于高版本。
- 单词级别已是目前 NLP + OCR 识别的极限,不要妄想识别拼音等更细颗粒度的操作,这个层面需要神经网络方面的科学家介入。
结论
- iOS 纯自研能力的表现在业内已是首屈一指,无需额外购买第三方渠道 SDK,故没有使用成本限制。
- 基于上一点,无额外包体积负担。
- 目前展示为 Demo 级别代码实现,介入业务功能需要额外工作处理细节。
- 需要开发的工作内容为
- 摄像头拍摄及拍摄后的相片内容展示
- Vision 识别处理、版本隔离等
- NaturalLanguage 分词、语种处理
- 斜体矫正等边界细节处理
- 渲染绘制处理
- 手势处理&响应
- 服务器翻译请求
- 翻译内容弹窗交互及响应逻辑等
- 屏幕适配处理
- 业务埋点